#
Identifiers
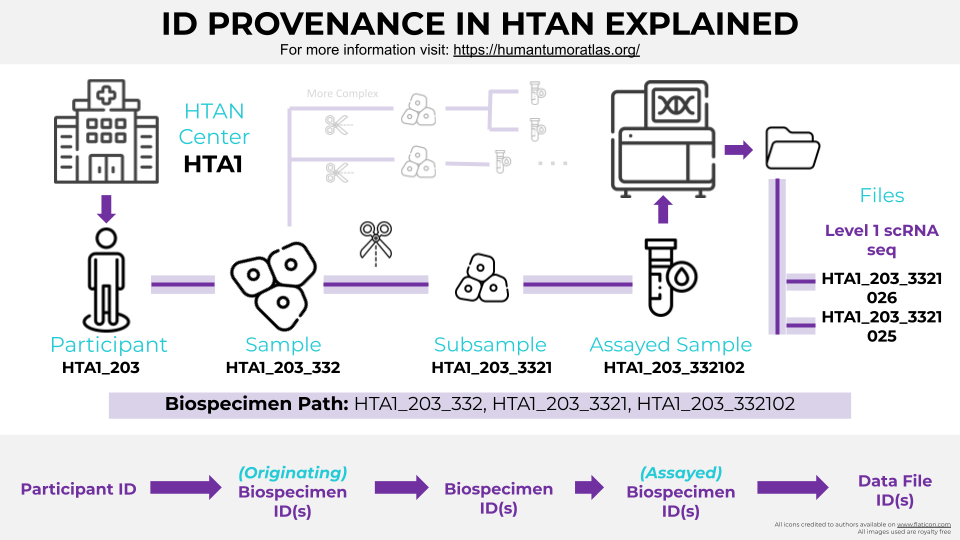
All research participants, biospecimens and derived data within HTAN are associated with a unique HTAN identifier.
Research participants are identified with the following pattern:
<participant_id> ::= <htan_center_id>_integerWhere the htan_center_id is the HTAN Center Prefix. (e.g. HTA1, HTA2) Please see HTAN Centers for a full list of HTAN Center prefixes.
Derivative data includes anything derived from a research participant, including biospecimens such as samples, tissue blocks, slides, aliquots, analytes, and data files that result from assaying those biospecimens. These identifiers follow the pattern:
<derivative_entity_id> ::= <participant_id>_integerFor example, if research participant 1 within the CHOP project (HTA4) has provided three samples, you would have three HTAN IDs, such as:
HTA4_1_1
HTA4_1_3
HTA4_1_8
#
Special Identifiers
If a single data file is generated from one of those samples, that file could have an HTAN ID such as:
HTA4_1_42If a single data file is derived from more than one participant, the file identifier may contain a wildcard string e.g. ‘0000’, after the HTAN center identifier. For example:
HTA4_0000_1
HTA4_0000_2
HTA4_0000_3If a data file is derived from an external control participant, the biospecimen and file identifiers will contain the string ‘EXT’ before the external control participant integer. For example:
HTA4_EXT1_1
HTA4_EXT2_2
HTA4_EXT3_3More detailed information about HTAN Identifiers may be found in the HTAN Identifiers SOP.
#
ID to ID linkages
Note that the explicit linking of participants to biospecimens to assays is not encoded in the HTAN Identifier. Rather, the linking is encoded in explicit metadata elements (see Relationship Model).